“Shorter Tokens Are More Likely” by Brendan Long
- Author
- LessWrong ([email protected])
- Published
- Sun 24 Aug 2025
- Episode Link
- https://www.lesswrong.com/posts/iZPKuuWsDXAcQWbLJ/shorter-tokens-are-more-likely
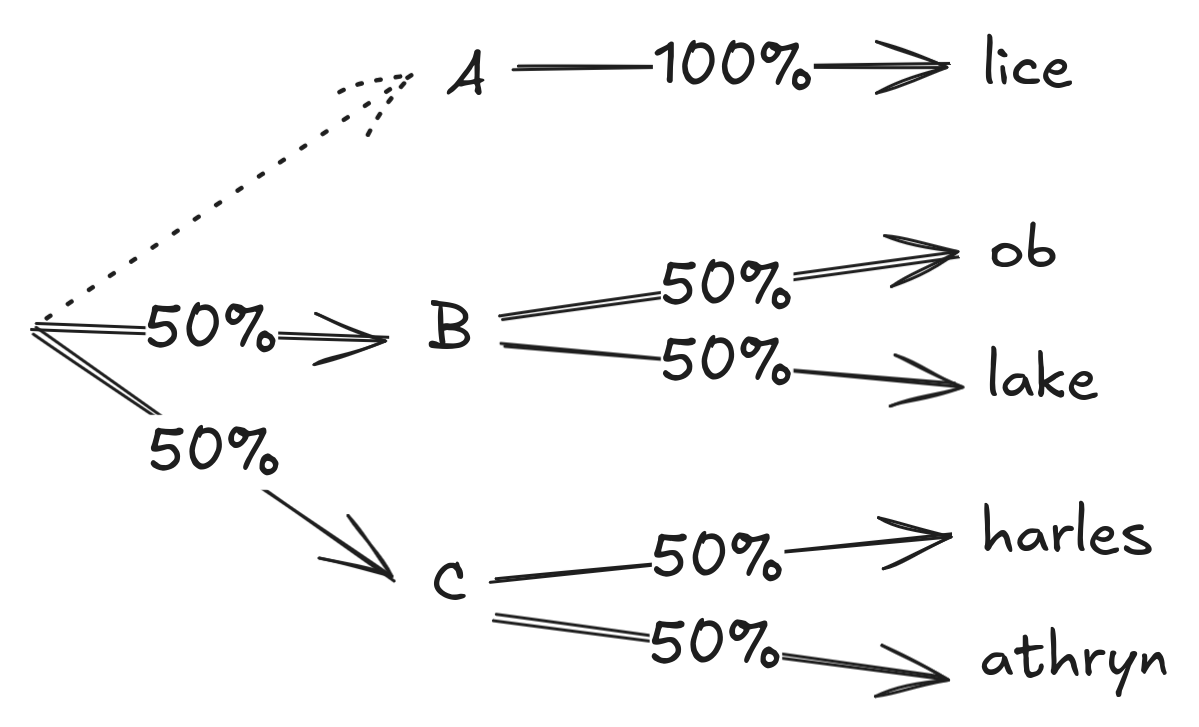
I was thinking about LLM tokenization (as one does) and had a thought: We select the next output token for an LLM based on its likelihood, but shorter tokens are more likely.
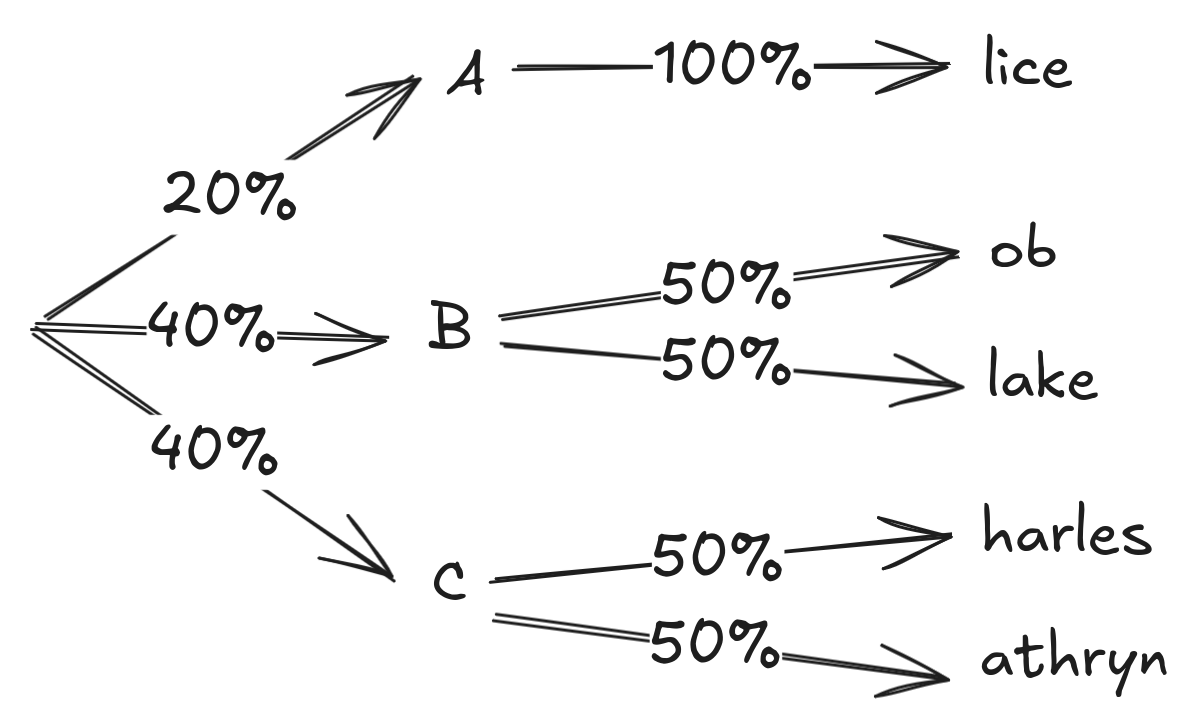
Why? Shorter common tokens are (correctly) learned to be higher-probability because they have the combined probability of any word they could complete. However, standard generation techniques will only consider a subset of probabilities and scale the largest probabilities. Both of these will take the highest probabilities and increase them further, meaning short/common tokens become significantly more likely to be generated just because they're shorter.
I ran an experiment to investigate this, showing that the first-character distribution of words generated by nanoGPT[1] is similar regardless of tokenization without top-K or temperature scaling, but if we use common settings (top-K=200 and temperature=0.8), we can increase the likelihood that a word starts with 'c' from 4% up to 10% just [...]
---
Outline:
(01:36) Why?
(02:27) Top-K Sampling
(02:52) Temperature 1.0
(04:19) The Experiment
(05:42) Results
(06:47) Shakespeare Experiment
(07:08) Results
(08:15) Why Does It Matter?
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
August 24th, 2025
Source:
https://www.lesswrong.com/posts/iZPKuuWsDXAcQWbLJ/shorter-tokens-are-more-likely
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
