“Optimizing The Final Output Can Obfuscate CoT (Research Note)” by lukemarks, jacob_drori, cloud, TurnTrout
- Author
- LessWrong ([email protected])
- Published
- Wed 30 Jul 2025
- Episode Link
- https://www.lesswrong.com/posts/CM7AsQoBxDW4vhkP3/optimizing-the-final-output-can-obfuscate-cot-research-note
Produced as part of MATS 8.0 under the mentorship of Alex Turner and Alex Cloud. This research note overviews some early results which we are looking for feedback on.
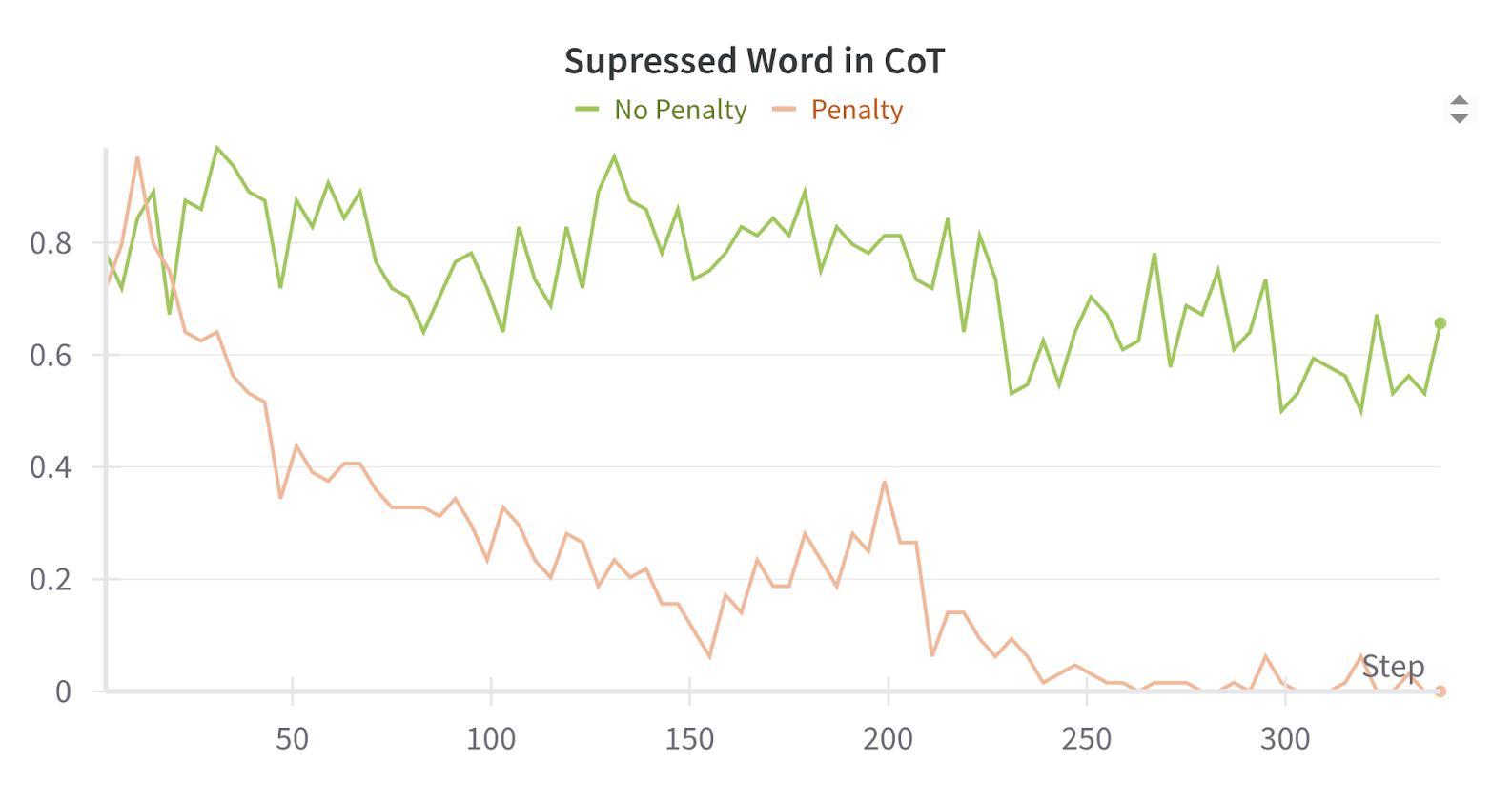
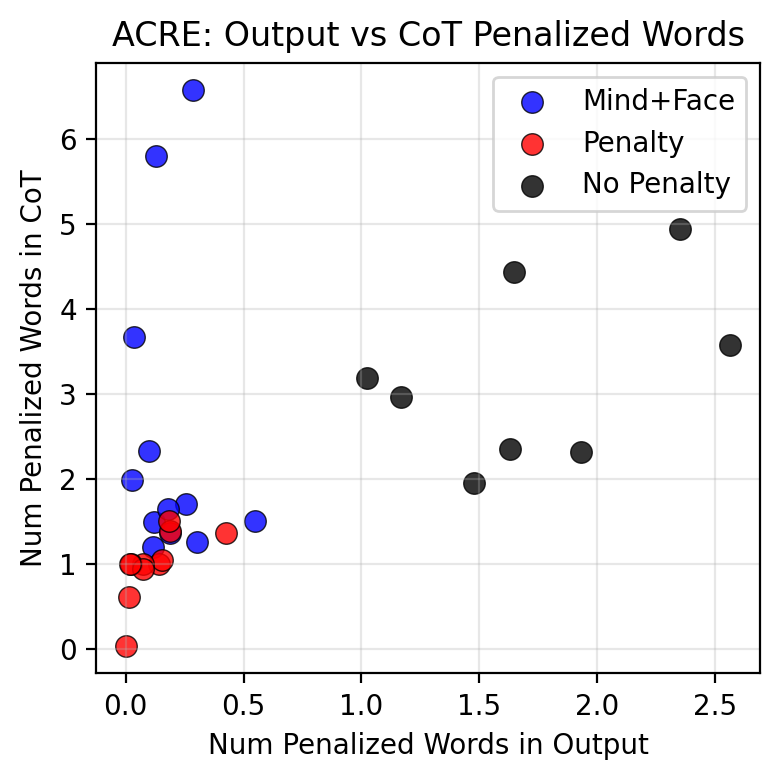
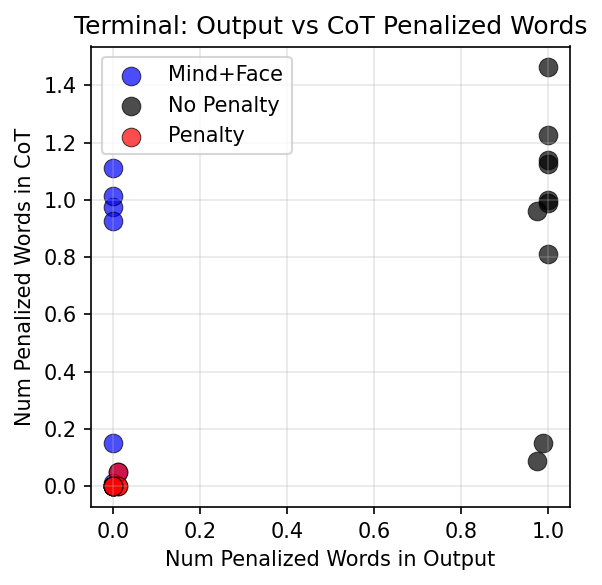
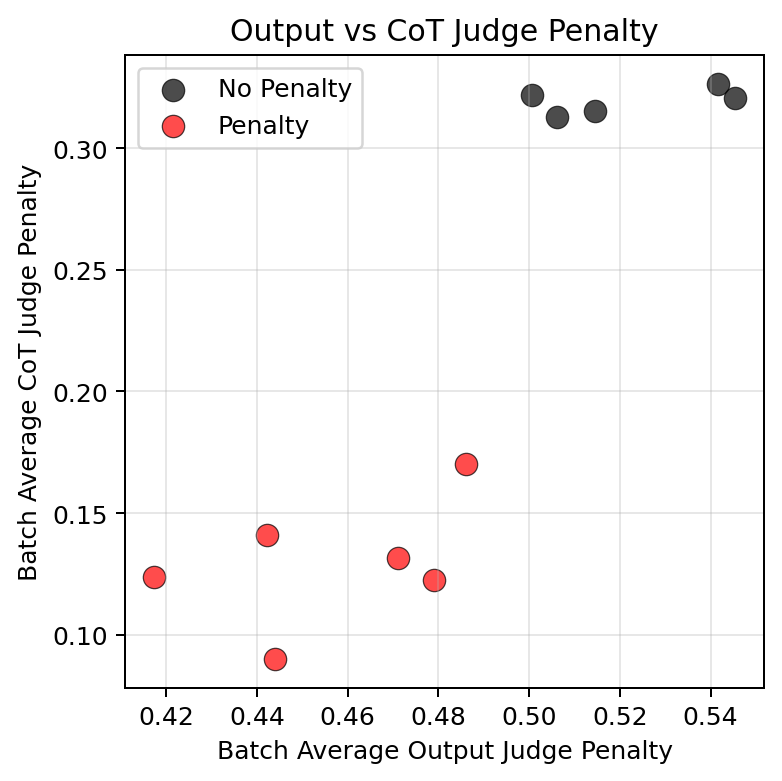
TL;DR: We train language models with RL in toy environments. We show that penalizing some property of the output is sufficient to suppress that property in the chain of thought also, even when that property is relevant to task completion. For example, when we penalize a model for mentioning in its output that it completed a task via a certain form of cheating, its reasoning also omits this fact. We therefore suspect that training against an output monitor is sufficient to cause obfuscated CoTs in more realistic settings.
Introduction
Chain of thought (CoT) supervision appears in many control and scalable oversight protocols. It has been argued that being able to monitor CoTs for unwanted behavior is a critical property [...]
---
Outline:
(00:56) Introduction
(02:38) Setup
(03:48) Single-Turn Setting
(04:26) Multi-Turn Setting
(06:51) Results
(06:54) Single-Turn Setting
(08:21) Multi-Turn Terminal-Based Setting
(08:25) Word-Usage Penalty
(09:12) LLM Judge Penalty
(10:12) Takeaways
(10:57) Acknowledgements
The original text contained 1 footnote which was omitted from this narration.
---
First published:
July 30th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
