“AI companies have started saying safeguards are load-bearing” by Zach Stein-Perlman
- Author
- LessWrong ([email protected])
- Published
- Wed 27 Aug 2025
- Episode Link
- https://www.lesswrong.com/posts/Bz2gPtqRJJDWyKxnX/ai-companies-have-started-saying-safeguards-are-load-bearing
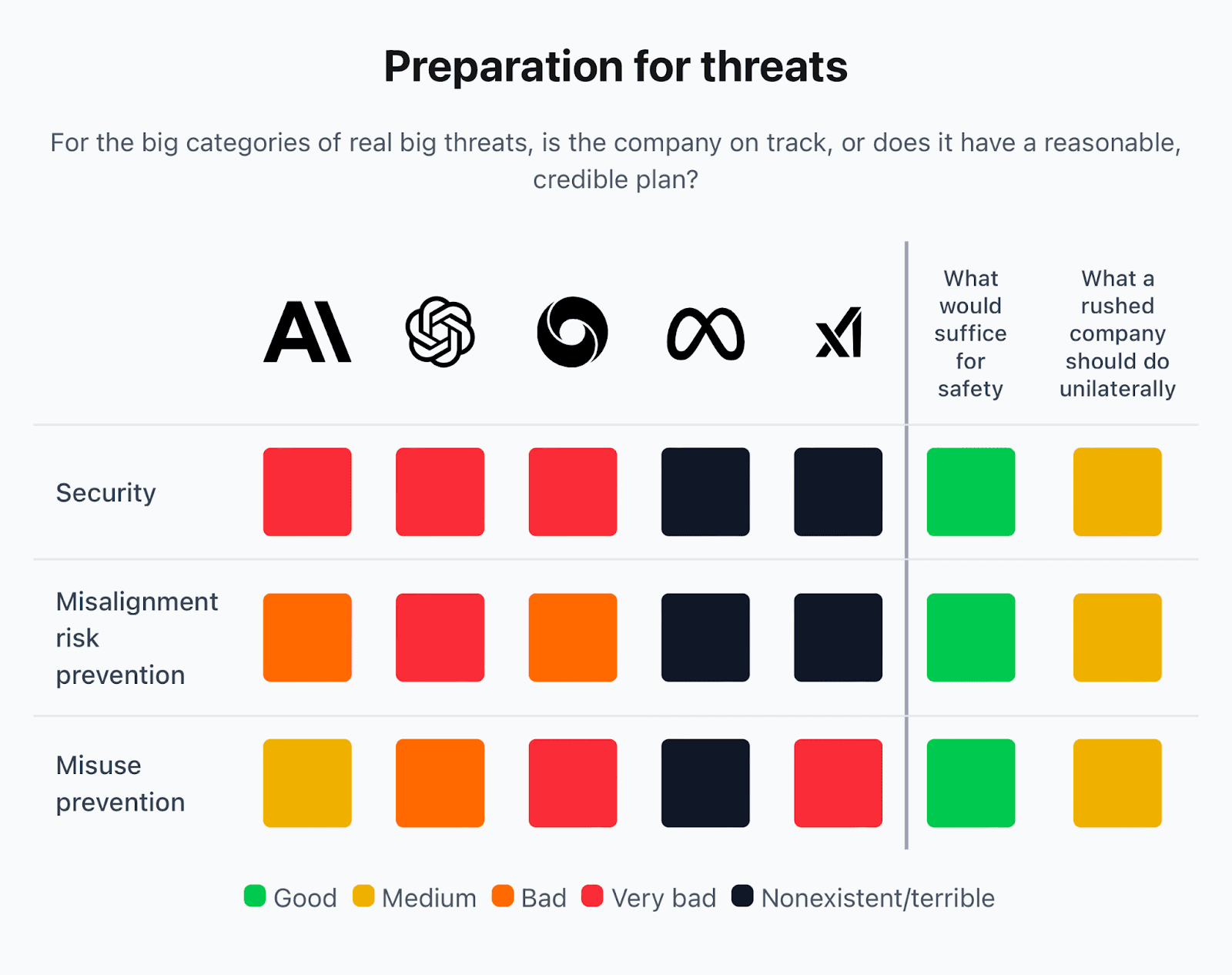
There are two ways to show that an AI system is safe: show that it doesn't have dangerous capabilities, or show that it's safe even if it has dangerous capabilities. Until three months ago, AI companies said their models didn't have dangerous capabilities. (At the time, I wrote that the companies' eval reports didn't support their claims that their models lacked dangerous bio capabilities.) Now, Anthropic, OpenAI, Google DeepMind, and xAI say their most powerful models might have dangerous biology capabilities and thus could substantially boost extremists—but not states—in creating bioweapons. To prevent such misuse, they must (1) prevent extremists from doing misuse via API and (2) prevent extremists from acquiring the model weights.[1] For (1), they claim classifiers block bad model outputs; for (2), they claim their security prevents extremists from stealing model weights.[2]
Are the new safety claims valid? On security, companies either aren't claiming to be [...]
---
Outline:
(01:57) Companies safeguards for bio capabilities
(06:21) Companies planning for future safeguards
(10:14) Small scorecard
The original text contained 8 footnotes which were omitted from this narration.
---
First published:
August 27th, 2025
---
Narrated by TYPE III AUDIO.
---
Images from the article:

Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
